
Abstract
Assistive agents should make humans' lives easier. Classically, such assistance is studied through the lens of inverse reinforcement learning, where an assistive agent (e.g., a chatbot, a robot) infers a human's intention and then selects actions to help the human reach that goal. This approach requires inferring intentions, which can be difficult in high-dimensional settings. We build upon prior work that studies assistance through the lens of empowerment: an assistive agent aims to maximize the influence of the human's actions such that they exert a greater control over the environmental outcomes and can solve tasks in fewer steps. We lift the major limitation of prior work in this area---scalability to high-dimensional settings---with contrastive successor representations. We formally prove that these representations estimate a similar notion of empowerment to that studied by prior work and provide a ready-made mechanism for optimizing it. Empirically, our proposed method outperforms prior methods on synthetic benchmarks, and scales to Overcooked, a cooperative game setting. Theoretically, our work connects ideas from information theory, neuroscience, and reinforcement learning, and charts a path for representations to play a critical role in solving assistive problems.
Our Method: Empowerment via Successor Representations
Our core contribution is a novel objective for training agents that are intrinsically motivated to assist humans without requiring a model of the human's reward function. Our objective, Empowerment via Successor Representations (ESR), maximizes the influence of the human's actions on the environment, and, unlike past approaches for assistance without reward inference, is based on a scalable model-free objective that can be derived from learned successor features encoding the states the human may want to reach given their action. Our effective empowerment objective enables the human to reach desired states without needing to infer their reward function.
Our method learns three representations:
- $\phi(s,\ar,\ah)$ – This representation can be understood as a sort of latent-space model, predicting the future representation given the current state $s$ and the human's current action $\ah$ as well as the robot's current action $\ar$.
- $\phi'(s,\ar)$ – This representation can be understood as an uncontrolled model, predicting the representation of a future state without reference to the current human action $\ah$. This representation is analogous to a value function.
- $\psi(s^+)$ – This is a representation of a future state.
We then use these learned representations to compute the approximate empowerment reward:
$$r(s, \ar) = \bigl(\phi(s_t, \ar, \ah) - \phi(s_t, \ar)\bigr)^T \psi(g)$$which we use to train an assistive policy without estimating the human's reward.
Analyzing the Effective Empowerment Objective
The key insight behind the ESR algorithm is that by maximizing a notion of human empowerment in the environment, the effective empowerment, we avoid needing to infer the human's objectives (or know them in advance).

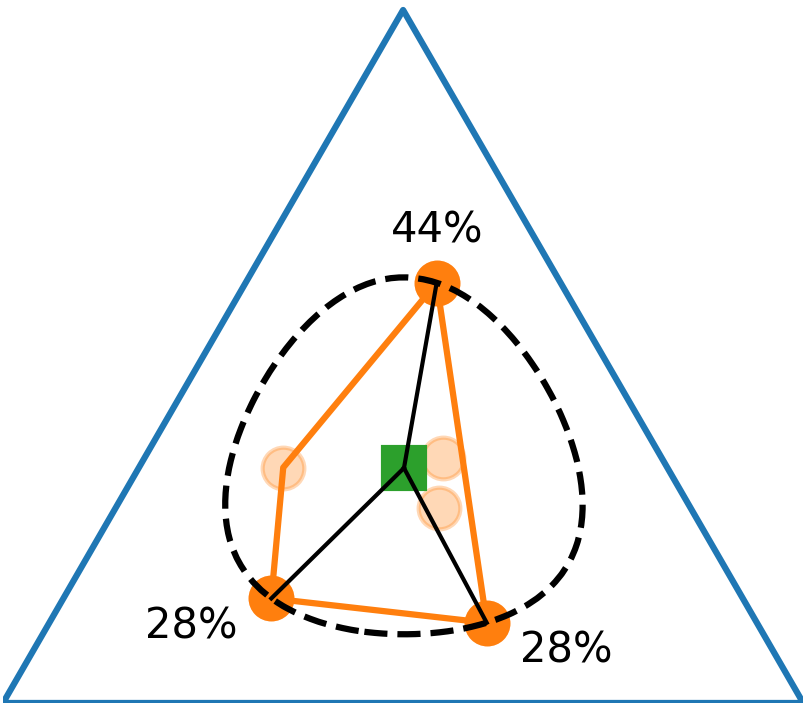
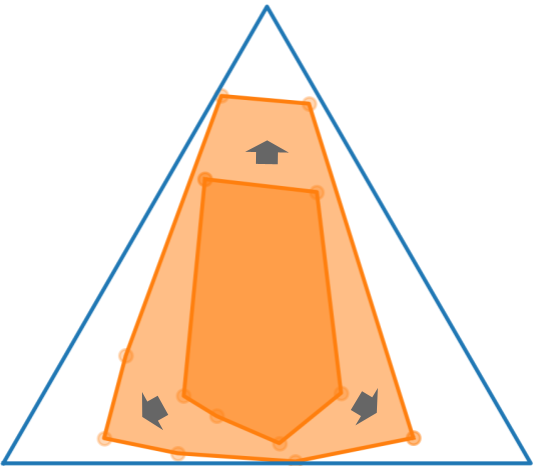
(a) State marginal polytope
(b) Mutual information
(c) Maximizing effective empowerment
In the special case where the human is maximizing a family of reward functions for different skills, we show that empowerment enables optimal assistance.
Visualizing Training and the Learned Representations

Results
Our ESR approach learns to assist a simulated human in a Gridworld environment augmented with varying numbers of obstacles. As the complexity of the environment increases, ESR remains effective, while the other assistance algorithms struggle.

We also evaluate our method in the Overcooked environment, a cooperative cooking game. We find that ESR outperforms prior methods that assist the human without knowing their reward function.

${\bf B\kern-.05em{\small I\kern-.025em B}\kern-.08em T\kern-.1667em\lower.7ex\hbox{E}\kern-.125emX}$
@inproceedings{myers2024learninga,
author = {Myers, Vivek and Ellis, Evan and Levine, Sergey and Eysenbach, Benjamin and Dragan, Anca},
booktitle = {{Conference} on {Neural Information Processing Systems}},
month = dec,
title = {{Learning} to {Assist Humans} without {Inferring Rewards}},
year = {2024},
}